नई दिल्ली — शोधकर्ताओं ने बताया कि जब बड़े भाषा मॉडल (Large Language Models - LLMs) को पौधों की विस्तृत जीनोमिक जानकारी पर प्रशिक्षित किया जाता है, तो ये मॉडल जीन के कार्यों और नियंत्रण तत्त्वों (regulatory elements) की सटीक भविष्यवाणी कर सकते हैं।
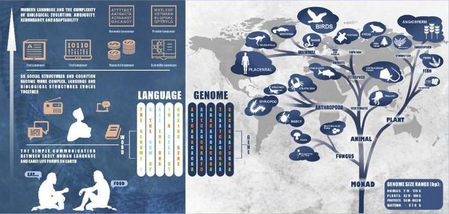
प्राकृतिक भाषा और जीनोमिक अनुक्रमों के बीच संरचनात्मक समानताओं का लाभ उठाकर ये एआई-संचालित मॉडल जटिल आनुवंशिक जानकारी को समझने में सक्षम हो जाते हैं, जिससे पौधों की जीवविज्ञान में अभूतपूर्व अंतर्दृष्टि मिलती है।
यह प्रगति फसलों की उन्नति को तेज करने, जैव विविधता संरक्षण को बढ़ाने और वैश्विक चुनौतियों के बीच खाद्य सुरक्षा को मजबूत करने की दिशा में एक महत्वपूर्ण कदम मानी जा रही है, जैसा कि यह अध्ययन Tropical Plants जर्नल में प्रकाशित हुआ है।
पारंपरिक रूप से, पौधों की जीनोमिक्स को जटिल और विशाल डाटा सेट्स की वजह से कठिन माना गया है, जहां पारंपरिक मशीन लर्निंग मॉडल की सीमाएं और एनोटेटेड डाटा की कमी बाधा बनती रही हैं।
हालांकि LLMs ने प्राकृतिक भाषा प्रसंस्करण (NLP) जैसे क्षेत्रों में क्रांति ला दी है, लेकिन इनका उपयोग पौधों की जीनोमिक्स में अभी प्रारंभिक अवस्था में ही है। सबसे बड़ी चुनौती इन मॉडलों को पौधों के जीनोमिक "भाषा" को समझने के लिए अनुकूलित करना रहा है, जो मानव भाषा के पैटर्न से काफी अलग होती है।
इस अध्ययन में, शोधकर्ताओं ने पौधों की जीनोमिक्स में LLMs की संभावनाओं की पड़ताल की।
प्राकृतिक भाषा और डीएनए अनुक्रमों के बीच समानता दर्शाते हुए, अध्ययन में यह दिखाया गया कि LLMs को जीन के कार्यों, नियंत्रण तत्वों और अभिव्यक्ति पैटर्न को समझने व अनुमान लगाने के लिए प्रशिक्षित किया जा सकता है।
शोध में DNABERT (केवल एन्कोडर मॉडल), DNAGPT (केवल डिकोडर मॉडल), और ENBED (एन्कोडर-डिकोडर मॉडल) जैसे विभिन्न LLM आर्किटेक्चर पर चर्चा की गई है।
टीम ने इन मॉडलों को पौधों की विशाल जीनोमिक डेटा पर पहले प्री-ट्रेनिंग दी और फिर विशेष रूप से एनोटेटेड डाटा के साथ फाइन-ट्यून किया जिससे सटीकता और भी बढ़ गई।
डीएनए अनुक्रमों को भाषा के वाक्यों की तरह मानते हुए, इन मॉडलों ने आनुवंशिक कोड में पैटर्न और संबंधों की पहचान की।
ये मॉडल प्रोमोटर की पहचान, एन्हांसर की खोज, और जीन अभिव्यक्ति विश्लेषण जैसे कार्यों में प्रभावशाली साबित हुए हैं। विशेष रूप से AgroNT और FloraBERT जैसे पौधा-केंद्रित मॉडल विकसित किए गए हैं, जो पौधों के जीनोम की व्याख्या और ऊतक-विशिष्ट जीन अभिव्यक्ति की भविष्यवाणी में बेहतर प्रदर्शन दिखा रहे हैं।
हालांकि, अध्ययन यह भी बताता है कि मौजूदा अधिकांश LLMs जानवरों या सूक्ष्मजीवों के डाटा पर प्रशिक्षित हैं, जहां व्यापक जीनोमिक एनोटेशन की कमी होती है। इसके बावजूद, पौधों की विभिन्न प्रजातियों में LLMs की बहुमुखी प्रतिभा और मजबूती को यह दर्शाता है।
सार रूप में, यह अध्ययन इस बात को रेखांकित करता है कि किस प्रकार कृत्रिम बुद्धिमत्ता, विशेष रूप से बड़े भाषा मॉडल, पौधों की जीनोमिक अनुसंधान में क्रांतिकारी परिवर्तन ला सकते हैं। यह अध्ययन हैनान विश्वविद्यालय की टीम — मेइलिंग झोउ, हैईवेई चाई और झीकियांग शा द्वारा किया गया।
With inputs from IANS









Copyright © Mid Time. All Rights Reserved
 Powered By Aptilogic Software
Powered By Aptilogic Software